We’re all used to updating our Windows Server operating systems with the Windows Update GUI, but did you know that you can update your server using command prompt and “sconfig”?
The past few years I’ve been managing quite a few Windows Server Core Instances that as we all know, do not have a GUI. In order to update those instances, you need to run Windows Update using the command line, but this method actually also works on normal Windows Server instances with the GUI as well!
Please enjoy this video or read on for why and how!
Why?
Using a GUI is great, however sometimes it’s not needed, and sometimes it even causes problems if it looses the backend connection where it’s pulling the data from. I’ve seen this true on newer Windows operating systems where the Windows Update GUI stops updating and you just sit there thinking the updates are running, when they are actually all complete.
The GUI also creates additional overhead and clutter. If there was an easier alternative to perform this function, wouldn’t it just make sense?
On Windows Server instances that have a GUI, I find it way faster and more responsive to just open an elevated (Administrative) command prompt, and kick off Windows Updates from there.
How
You can use this method on all modern Windows Server versions:
- Windows Server (with a GUI)
- Windows Server Core (without a GUI)
This also works with Windows Server Update Services so you can use this method either connecting to Windows Update (Microsoft Update) or Windows Server Update Services (WSUS).
Now lets get started!
- Open an Administrative (elevated) command prompt
- Run “sconfig” to launch the “Server Configuration” application
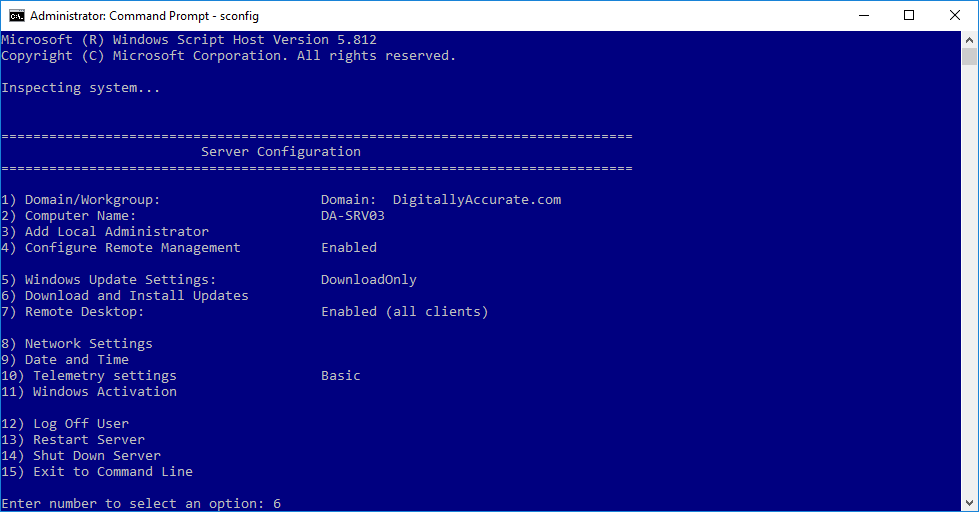
- Select option “6” to “Download and Install Windows Updates”
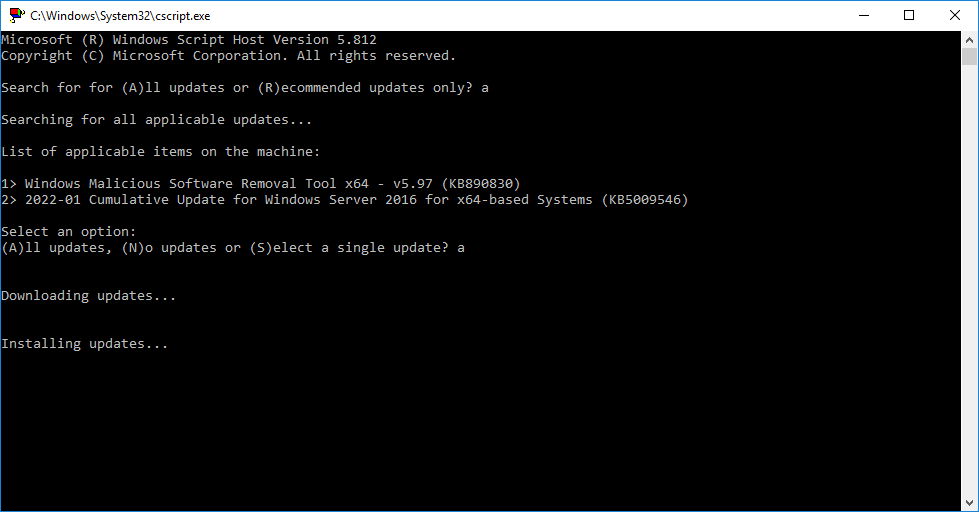
- Choose “A” for all updates, or “R” for recommended updates, and a scan will start
- After the available updates are shown, choose “A” for all updates, “N” for no updates, or “S” for single update selection
After performing the above, the updates will download and install.
I find it so much easier to use this method when updating many/multiple servers instead of the GUI. Once the updates are complete and you’re back at the “Server Configuration” application, you can use option “13” to restart Windows.