
This weekend I came across a big issue with my HPE MSA 2040 where one of the SAN controllers became unresponsive, and appeared to had failed because it would not boot.
It all started when I decided to clean the MSA SAN. I try to clean the components once or twice a year to remove dust and make sure it’s not getting all jammed up. Sometimes I’ll shut the entire unit down and remove the individual components, other times I’ll remove them while operating. Because of the redundancies and since I have two controllers, I can remove and clean each controller individually at separate times.
Please Note: When dusting equipment with fans, never allow the fans to spin up with compressed air as this can generate current which can damage components. Never allow compressed air flow to spin up fans.
After cleaning out the power supplies, it came time to clean the controllers.
The Problem
As always, I logged in to the SMU to shutdown controller A (storage). I shut it down, the blue LED illuminated it was safe for removal. I then proceeded to remove it, clean it, and re-insert it. The controller came back online, and ownership of the applicable disk groups were successfully moved back. Controller A was now completed successfully. I continued to do the same for controller B: I logged in to shutdown controller B (storage). It shut down just like controller A, the blue LED removable light illuminated. I was able to remove it, clean it, and re-insert it.
However, controller B did not come back online.
After inserting controller B, the status light was flashing (as if it was booting). I waited 20 minutes with no change. The SMU on controller B was responding to HTTPS requests, however you could not log on due to the error “system is initializing”. SSH was functioning and you could log in and issue commands, however any command to get information would return “Please wait while this information is pulled from the MC controller”, and ultimately fail. The SMU on controller A would report a controller fault on controller B, and not provide any other information (including port status on controller B).
I then tried to re-seat the controller with the array still running. Gave it plenty of time with no effect.
I then removed the failed controller, shutdown the unit, powered it back on (only with controller A), and re-inserted Controller B. Again, no effect.
The Fix
At this point I’m thinking the controller may have failed or died during the cleaning process. I was just about to call HPE support for a replacement until I noticed the “Power LED” light inside of the failed controller would flash every 5 seconds while removed.
This made me start to wonder if there was an issue writing the cache to the compact flash card, or if the controller was still running off battery power but had completely frozen.
I tried these 3 things on the failed controller while it was unplugged and removed:
- I left the controller untouched for 1 hour out of the array (to maybe let it finish whatever it was doing while on battery power)
- There’s an unlabeled button on the back of the controller. As a last resort (thinking it was a reset button), I pressed and held it for 20 seconds, waited a minute, then briefly pressed it for 1 second while it was out of the unit.
- I removed the Compact Flash card from the controller for 1 minute, then re-inserted it. In hoping this would fail the cache copy if it was stuck in the process of writing cache to compact flash.
I then re-inserted the controller, and it booted fine! It was not functioning and working (and came up very fast). Looking at the logs, it has no record of what occurred between the first shutdown, and final boot. I hope this post helps someone else with the same issue, it can save you a support ticket, and time with a controller down.
Disclaimer
PLEASE NOTE: I could not find any information on the unlabeled button on the controller, and it’s hard to know exactly what it does. Perform this at your own risk (make sure you have a backup). Since I have 2 controllers, and my MSA 2040 was running fine on Controller A, I felt comfortable doing this, as if this did reset controller B, the configuration would replicate back from controller A. I would not do this in a single controller environment.
Update – 24 Hours later
After I got everything up and running, I checked the logs of the unit and couldn’t find anything on controller B that looked out of ordinary. However, 24 hours later, I logged back in and noticed some new events showed up from the day before (from the day I had the issues):
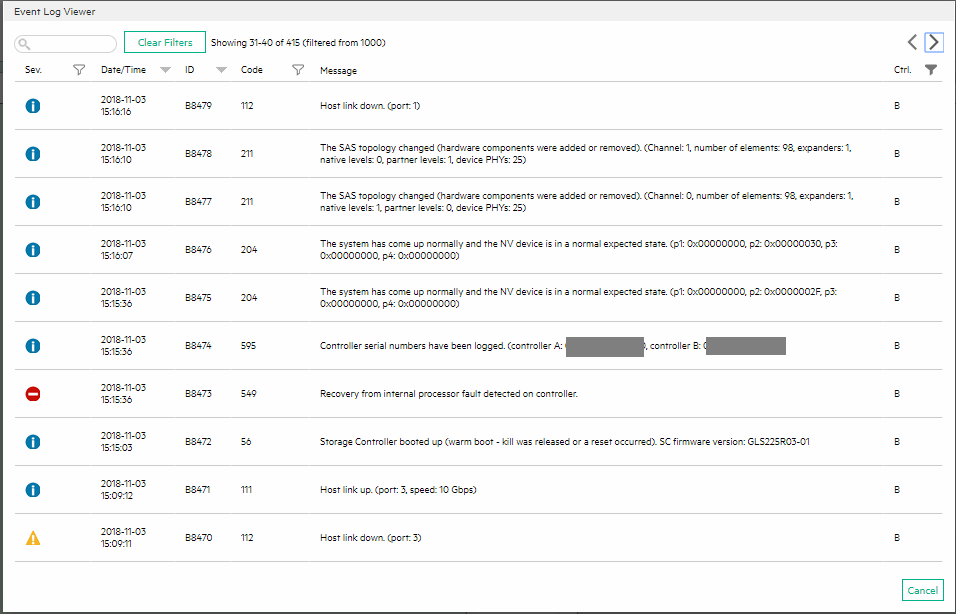
You’ll notice the event log with severity error:
Recovery from internal processor fault detected on controller. Code 549
One thing that’s very odd is that I know for a fact the time is wrong on the error severity log entry, this could be due to the fact we had a daylight savings time change last night at midnight. Either way it appears that it finally did detect that the Storage controller was in an error state and logged it, but it still would have been nice for some more information.
On a final note, the unit has been running perfectly for over 24 hours.
Update – April 2nd 2019
Well, in March a new firmware update was released for the MSA. I went to upgrade and the same issue as above occurred. During the firmware upgrade, at one point of the firmware update process a step had failed and repeated 4 times until successful.
The firmware update log (below was repeated):
Updating system configuration files System configuration complete Loading SC firmware. STATUS: Updating Storage Controller firmware. Waiting 5 seconds for SC to shutdown. Shutdown of SC successful. Sending new firmware to SC. Updating SC Image:Remaining size 6263505 Updating SC Image:Remaining size 5935825 Updating SC Image:Remaining size 5608145 Updating SC Image:Remaining size 5280465 Updating SC Image:Remaining size 4952785 Updating SC Image:Remaining size 4625105 Updating SC Image:Remaining size 4297425 Updating SC Image:Remaining size 3969745 Updating SC Image:Remaining size 3642065 Updating SC Image:Remaining size 3314385 Updating SC Image:Remaining size 2986705 Updating SC Image:Remaining size 2659025 Updating SC Image:Remaining size 2331345 Updating SC Image:Remaining size 2003665 Updating SC Image:Remaining size 1675985 Updating SC Image:Remaining size 1348305 Updating SC Image:Remaining size 1020625 Updating SC Image:Remaining size 692945 Updating SC Image:Remaining size 365265 Updating SC Image:Remaining size 37585 Waiting for Storage Controller to complete programming. Please wait... Please wait... Please wait... Please wait... Storage Controller has completed programming. Got an error (138) on firmware packet CAPI error: Firmware Update failed. Controller needs to reboot. Waiting 5 seconds for SC to shutdown. Shutdown of SC successful. Sending new firmware to SC. Updating SC Image:Remaining size 6263505 Updating SC Image:Remaining size 5935825 Updating SC Image:Remaining size 5608145 Updating SC Image:Remaining size 5280465 Updating SC Image:Remaining size 4952785 Updating SC Image:Remaining size 4625105 Updating SC Image:Remaining size 4297425 Updating SC Image:Remaining size 3969745 Updating SC Image:Remaining size 3642065 Updating SC Image:Remaining size 3314385 Updating SC Image:Remaining size 2986705 Updating SC Image:Remaining size 2659025 Updating SC Image:Remaining size 2331345 Updating SC Image:Remaining size 2003665 Updating SC Image:Remaining size 1675985 Updating SC Image:Remaining size 1348305 Updating SC Image:Remaining size 1020625 Updating SC Image:Remaining size 692945 Updating SC Image:Remaining size 365265 Updating SC Image:Remaining size 37585 Waiting for Storage Controller to complete programming. Please wait... Please wait... Storage Controller has completed programming. Got an error (138) on firmware packet CAPI error: Firmware Update failed. Controller needs to reboot. Waiting 5 seconds for SC to shutdown. Shutdown of SC successful. Sending new firmware to SC. Updating SC Image:Remaining size 6263505 Updating SC Image:Remaining size 5935825 Updating SC Image:Remaining size 5608145 Updating SC Image:Remaining size 5280465 Updating SC Image:Remaining size 4952785 Updating SC Image:Remaining size 4625105 Updating SC Image:Remaining size 4297425 Updating SC Image:Remaining size 3969745 Updating SC Image:Remaining size 3642065 Updating SC Image:Remaining size 3314385 Updating SC Image:Remaining size 2986705 Updating SC Image:Remaining size 2659025 Updating SC Image:Remaining size 2331345 Updating SC Image:Remaining size 2003665 Updating SC Image:Remaining size 1675985 Updating SC Image:Remaining size 1348305 Updating SC Image:Remaining size 1020625 Updating SC Image:Remaining size 692945 Updating SC Image:Remaining size 365265 Updating SC Image:Remaining size 37585 Waiting for Storage Controller to complete programming. Please wait... Please wait... Storage Controller has completed programming. Got an error (138) on firmware packet CAPI error: Firmware Update failed. Controller needs to reboot. Waiting 5 seconds for SC to shutdown. Shutdown of SC successful. Sending new firmware to SC. Updating SC Image:Remaining size 6263505 Updating SC Image:Remaining size 5935825 Updating SC Image:Remaining size 5608145 Updating SC Image:Remaining size 5280465 Updating SC Image:Remaining size 4952785 Updating SC Image:Remaining size 4625105 Updating SC Image:Remaining size 4297425 Updating SC Image:Remaining size 3969745 Updating SC Image:Remaining size 3642065 Updating SC Image:Remaining size 3314385 Updating SC Image:Remaining size 2986705 Updating SC Image:Remaining size 2659025 Updating SC Image:Remaining size 2331345 Updating SC Image:Remaining size 2003665 Updating SC Image:Remaining size 1675985 Updating SC Image:Remaining size 1348305 Updating SC Image:Remaining size 1020625 Updating SC Image:Remaining size 692945 Updating SC Image:Remaining size 365265 Updating SC Image:Remaining size 37585 Waiting for Storage Controller to complete programming. Please wait... Please wait... Storage Controller has completed programming. Updating SC Image:Remaining size 0 Storage Controller has been successfully updated. STATUS: Current CPLD firmware is up-to-date. CPLD update not required. ========================================== Software Component Load Summary: MC Software: SUCCESSFUL SC Software: SUCCESSFUL EC Software: NOT ATTEMPTED CPLD Software: NOT ATTEMPTED ==========================================
During the Storage Controller restarting process, the controller never came back up. I removed the controller 1 hour, re-inserted and the above fix did not work. I then tried it after 2 hours of disconnection.
At this point I contacted HPE, who is sending a replacement controller.
The following day (12 hours of controller removed), I re-inserted it again and it actually booted up, was working with the new firmware, and then did a PFU (Partner Firmware Update) of controller A.
While it is working now, I’m still going to replace the controller as I believe something is not functioning correctly.
Thank You for the great post it saved my life 🙂
I had exactly the same issue. It has begun with a host port IP setting.
After a few minutes controller B showed up the CopactFlash fault.
First i tryed to reboot the controller and aftert this step instant controller failure.
After it i unplugged the controller ad did the reset via your advice and a miracle is happened 🙂
Hi Barnabas,
Glad to hear it helped! Always be careful though, doing this will corrupt or clear the flash and compact flash on the controller… Only do this if the other controller is valid, responding, functioning properly, and has an OK status.
Cheers,
Stephen
Dear Steve,
We are migrating from Netapp to a HPE MSA 2050. I’ve just started to work with it and I got the error message. I have no experience with the HPE, but it looks fairly straight forward in installing, much better then the Netapp. I will be visiting your blog in the next couple of weeks whilst setting up the HPE. 😉
By the way is there a big difference between the 2040 and 2050?
Have a great day,
André
Glad to hear, the MSA storage arrays are beautiful products!
There is a few differences, the main being that the 205x series are the next generation agyer the 204x series.
Hi Stephen! My name is Alex, i got some problem with my MSA, I hope You can give me good advice. So, i Have two MC on HP MSA, each of MC connected via FibreChannel modules to HP Proliant Servers throught SAN switch. And there are dozen of VMs on servers. I need to replace MC B, without stopping (power off) whole MSA. How do You think, is it possible without data loss?
Hi Alex,
As long as you configured the unit properly, and have the proper channels of redundancy (which you likely do, if the controller has failed and everything is still working), you just simply follow the standard procedures for swapping the controller.
No data loss should occur if the unit was configured properly, and if you follow standard procedures.
Stephen
Stephen, thanx for fast answer, yeah, looks like everything configured good, but i have to be sure. Well, i do not really know, witch MC is bad, and a problem i have – a can’t see any mappings via web-interface or CLI, but DG, volumes and other stuff i can see clear. So, HP sent me new MC, i whatnt to make hot replace, but data in MSA very important…
You need to identify which controller is bad first.
Have you logged on to the SMU on both controllers? One should have good information.
No, i can\t see any mappings via A and via B MC. And in CLI – too, but “show volume-maps” – still works. And other one symptom – web-interface often unavailable, just disconnecting.
Have you tried to restart one of the management controllers (not the storage controller)?
What did HPe advise?
Are there any amber lights on the back of the storage controllers?
There is no any amber lights. All HP recommendations i made at all (restart of MSA, FW upgrade and downgrade, etc,) – no result. They sent me new MC and wants me to replace it, but i cant stop MSA in september…
Did you restart the Storage Controllers, or Management Controllers?
The storage controllers handle the actual storage, whereas the management controllers provide the CLI and SMU.
Sometimes the management controllers can crash, but everything still works. In this case it would require a restart of only the management controllers.
However, if you’ve restarted the SC’s, the MCs, and the entire SAN with no effect, I’m wondering if there could be an issue with the midplane or something.
When you log on to vSphere, are all paths active? If some paths are offline, you can use this to determine which storage controller may be problematic. In this case, if there are paths offline, I’d replace the storage controller that has the failed paths.
Yes, Stephen, i restarted MCs and SCs, and all the paths online…HPe 2 and 3 level support do not have descision still. As for me – some issue, that common for MCs: Compact Flash card trouble, Firmware trouble…Maybe the fact important that I use virtual volumes.
Hi Stephen,
I have HP MSA 2040 storage which we are going to repurpose. The device is stacked but I am unable to take its serial and it always says COM4/7 doesn’t exists. So, I reset the device and in next attempt I was able to connect through serial port and when i tried to reset it to default settings it started giving me below error.
(none) login: restoredefaults
Password:
2019-09-09 14:59:05: Running MC-only restoredefaults on partner controller.
2019-09-09 14:59:05: Running MC-only restoredefaults on this controller.
2019-09-09 14:59:05: Perform Restore Defaults
/app/default/restoreDefaults.sh: source: line 96: can’t open ‘/mem/relinfo/features.env’
So I dont know its password and i cant reset it as well. Any idea how to fix it?
Regards,
Sandeep
Hi Sandeep,
Can you try reflashing the firmware using the restoredefaults account? I’m not familiar with that account/method, but I’m curious if it’s possible.
Do you have active warranty? I’d check the serial number, and if it has warranty, try submitting a ticket with HPe.
Cheers,
Stephen
Hi Stephen,
I have HP MSA 2040 storage with two controllers and with D2700 disk enclosure with two controllers.
Now SMU periodically reports warning (The algorithm for best-path routing selected the alternate path to the indicated disk because the I/O error count on the primary path reached its threshold.) and then corresponding disk becomes degraded. I have blinking amber light 2 on controller B of D2700 which indicates SAS port error detected by application client). Now I already have 8 degraded disks of 12 disks on controller storage B of D2700.
How do you think, can I try to restart the storage controller B without any loss of data to fix this issue?
Hi Andrey,
First and foremost, make sure you have an active valid backup of the data.
I’d recommend contacting HPe and submitting a support ticket. It sounds like either a disk, backplane, D2700 controller, or SAS cable might not be functioning.
As for restarting controllers, if the path is failing on that controller, in a dual controller configuration you can simply restart it. However if it’s using that controller, I wouldn’t recommend doing that.
If you’re not going to call HPe support, I might actually recommend restarting the entire storage system properly and see what happens. But make sure you have a backup first as this could make the situation worse.
Stephen
Hi Stephen,
Thank you very much. I submitted a support ticket on HPe.