Today we take it back to basics with a guide on how to create an Active Directory Domain on Windows Server 2019.
These instructions are also valid for previous versions of Microsoft Windows Server.
This video will demonstrate and explain the process of installing, configuring, and deploying a Windows Server 2019 instance as a Domain Controller, DNS Server, and DHCP Server and then setting up a standard user.
I also have a newer guide on How to create an Active Directory Domain on Windows Server 2022!
Check it out and feel free to leave a comment! Scroll down below for more information and details on the guide.
Who’s this guide for
No matter if you’re an IT professional who’s just getting started or if you’re a small business owner (on a budget) setting up your first network, this guide is for you!
What’s included in the video
In this guide I will walk you through the following:
- Installing Windows Server 2019
- Documenting a new Server installation
- Configuring Network Settings
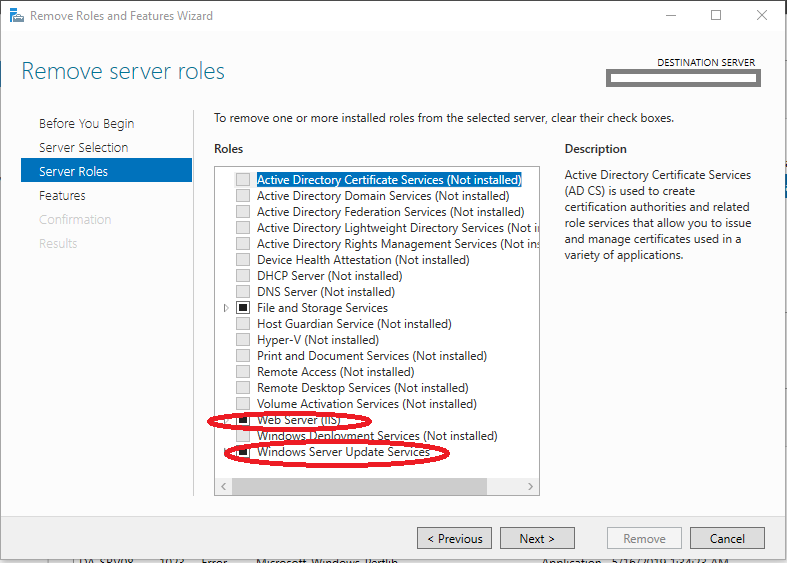
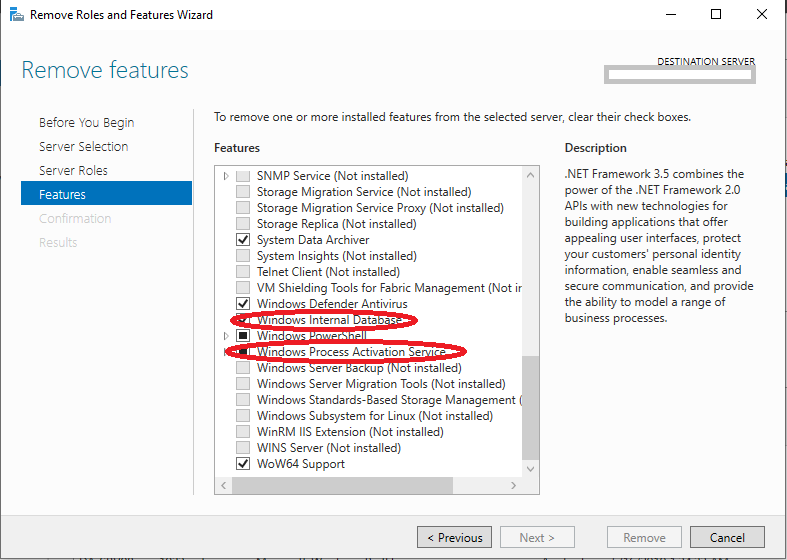
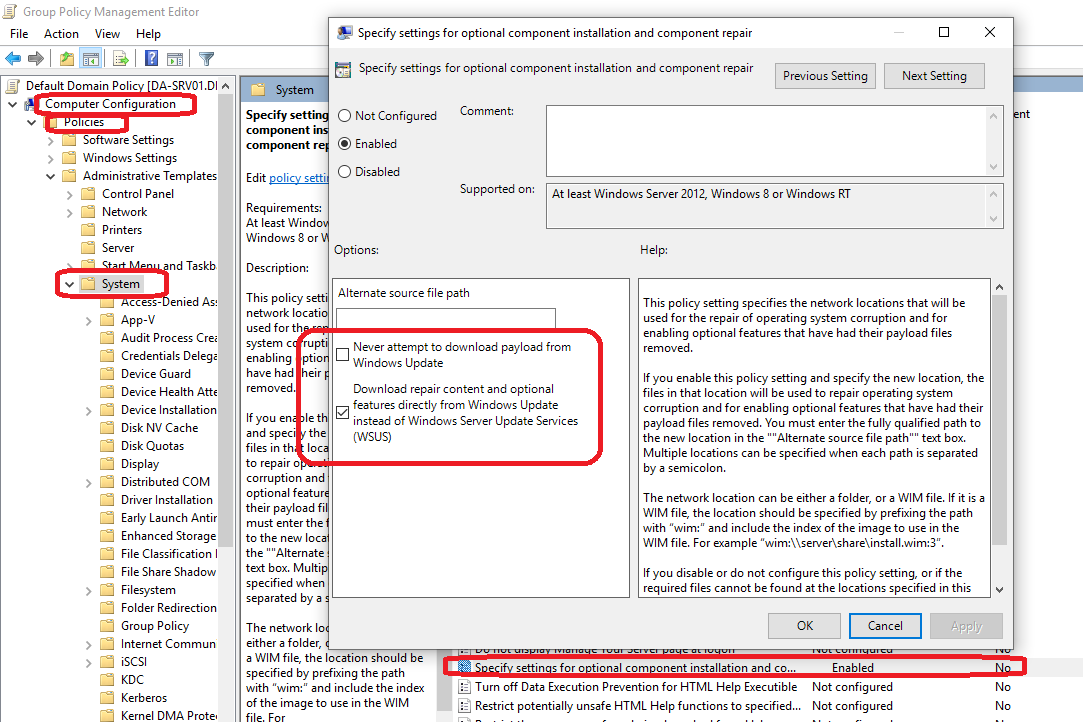
- Installation and configuration of Microsoft Active Directory
- Promote a server as a new domain controller
- Installation and configuration of DNS Role
- Installation and configuration of DHCP Role
- Setup and configuration of a new user account
What’s required
To get started you’ll need:
- 1 x Server (Virtual Machine or Physical Server)
- Microsoft Windows Server 2019 Licensing
- A network router and/or firewall
Hardware/Software used in this demonstration
- VMware vSphere
- HPE DL360p Gen8 Server
- Microsoft Windows Server 2019
- pfSense Firewall
Other blog posts referenced in the video
The following blog posts are mentioned in the video: