For over a year and a half I have been working on building a custom NVMe Storage Server for my homelab. I wanted to build a high speed storage system similar to a NAS or SAN, backed with NVMe drives that provides iSCSI, NFS, and SMB Windows File Shares to my network.
The computers accessing the NVMe Storage Server would include VMware ESXi hosts, Raspberry Pi SBCs, and of course Windows Computers and Workstations.
The focus of this project is on high throughput (in the GB/sec) and IOPS.
The current plan for the storage environment is for video editing, as well as VDI VM storage. This can and will change as the project progresses.
The History
More and more businesses are using all-flash NVMe and SSD based storage systems, so I figured there’s no reason why I can’t have build and have my own budget custom all NVMe flash NAS.
This is the story of how I built my own NVMe based Storage Server.
The first version of the NVMe Storage Server consisted of the IO-PEX40152 card with 4 x 2TB Sabrent Rocket 4 NVMe drives inside of an HPE Proliant DL360p Gen8 Server. The server was running ESXi with TrueNAS virtualized, and the PCIe card passed through to the TrueNAS VM.
The results were great, the performance was amazing, and both servers had access to the NFS export via 2 x 10Gb SFP+ networking.
There were three main problems with this setup:
Virtualized – Once a month I had an ESXi PSOD. This was either due to overheating of the IO-PEX40152 card because of modifications I made, or bugs with the DL360p servers and PCIe passthrough.
NFS instead of iSCSI – Because TrueNAS was virtualized inside of the host that was using it for storage, I had to use NFS since the host virtualizing TrueNAS would also be accessing the data on the TrueNAS VM. When shutting down the host, you need to shut down TrueNAS first. NFS disconnects are handled way healthier than iSCSI disconnects (which can cause corruption even if no files are being used).
CPU Cores maxed on data transfer – When doing initial testing, I was maxing out the CPU cores assigned to the TrueNAS VM because the data transfers were so high. I needed a CPU and setup that was better fit.
Version 1 went great, but you can see some things needed to be changed. I decided to go with a dedicated server, not virtualize TrueNAS, and go for a newer CPU with a higher Ghz speed.
And so, version 2 was born (built). Keep reading and scrolling for pictures!
The Hardware
On version 2 of the project, the hardware includes:
While the ML310e Gen8 v2 server is a cheap low entry server, it’s been a fantastic team member of my homelab.
HPE Dual 10G Port 560SFP+ adapters can be found brand new in unsealed boxes on eBay at very attractive prices. Using HPE Parts inside of HPE Servers, avoids the fans from spinning up fast.
The ML310e Gen8 v2 has some issues with passing through PCIe cards to ESXi. Works perfect when not passing through.
The new NVMe Storage Server
I decided to repurpose an HPE Proliant ML310e Gen8 v2 Server. This server was originally acting as my Nvidia Grid K1 VDI server, because it supported large PCIe cards. With the addition of my new AMD S7150 x2 hacked in/on to one of my DL360p Gen8’s, I no longer needed the GRID card in this server and decided to repurpose it.
HPe ML310e Gen8 v2 with NVMe Storage
I installed the IOCREST IO-PEX40152 card in to the PCIe 16x slot, with 4 x 2TB Sabrent Rocket 4 NVME drives.
IOCREST IO-PEX40152 with GLOTRENDS M.2 NVMe SSD Heatsink on Sabrent Rocket 4 NVME
While the server has a PCIe 16x wide slot, it only has an 8x bus going to the slot. This means we will have half the capable speed vs the true 16x slot. This however does not pose a problem because we’ll be maxing out the 10Gb NICs long before we max out the 8x bus speed.
HPE ML310e Gen8 v2 with IOCREST IO-PEX40152HPE ML310e Gen8 v2 with IOCREST IO-PEX40152
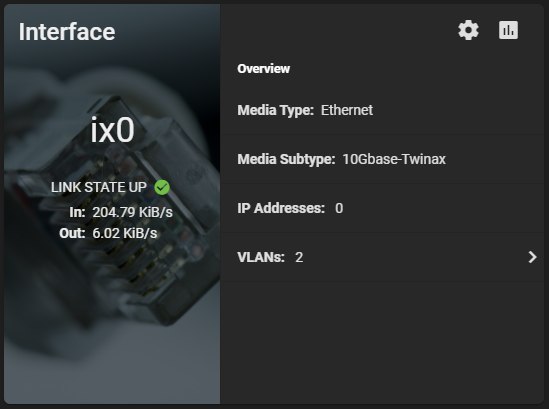
I also installed an HPE Dual Port 560SFP+ NIC in to the second slot. This will allow a total of 2 x 10Gb network connections from the server to the Ubiquiti UniFi US-16-XG 10Gb network switch, the backbone of my network.
HPE ML310e Gen8 v2 with HPE 560SFP+ and 10Gig DACHPE ML310e Gen8 v2 with HPE 560SFP+ and 10Gig DAC
The Server also have 4 x Hot Swappable HD bays on the front. When configured in HBA mode (via the BIOS), these are accessible by TrueNAS and can be used. I plan on populating these with 4 x 4TB HPE MDL SATA Hot Swappable drives to act as a replication destination for the NVMe pool and/or slower magnetic long-term storage.
HPE ML310e Gen8 v2 with Hotswap Drive bays
I may also try to give WD RED Pro drives a try, but I’m not sure if they will cause the fans to speed up on the server.
TrueNAS Installation and Configuration
For the initial Proof-Of-Concept for version 2, I decided to be quick and dirty and install it to a USB stick. I also waited until I installed TrueNAS on to the USB stick and completed basic configuration before installing the Quad NVMe PCIe card and 10Gb NIC. I’m using a USB 3.0 port on the back of the server for speed, as I can’t verify if the port on the motherboard is USB 2 or USB 3.
TrueNAS USB Stick on HPE ML310e Gen8 v2
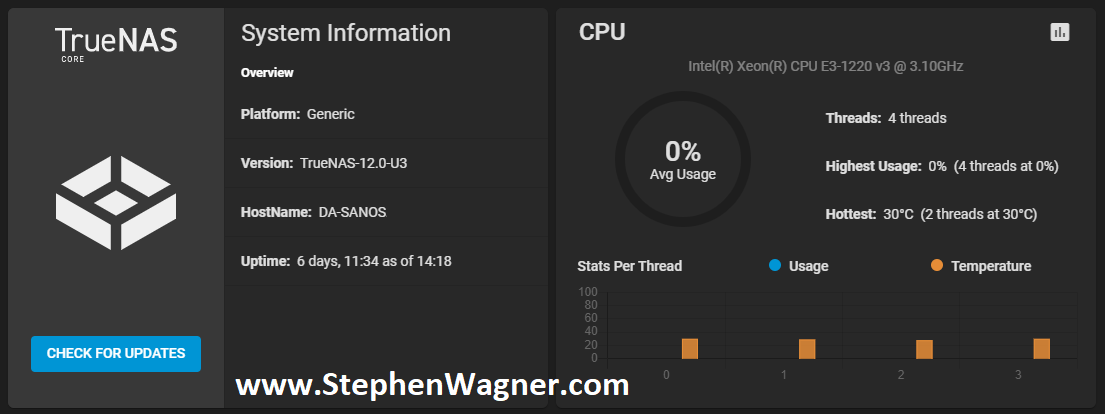
TrueNAS installation worked without any problems whatsoever on the ML310e. I configured the basic IP, time, accounts, and other generic settings. I then proceeded to install the PCIe cards (storage and networking).
TrueNAS Installed on NVMe Storage Server
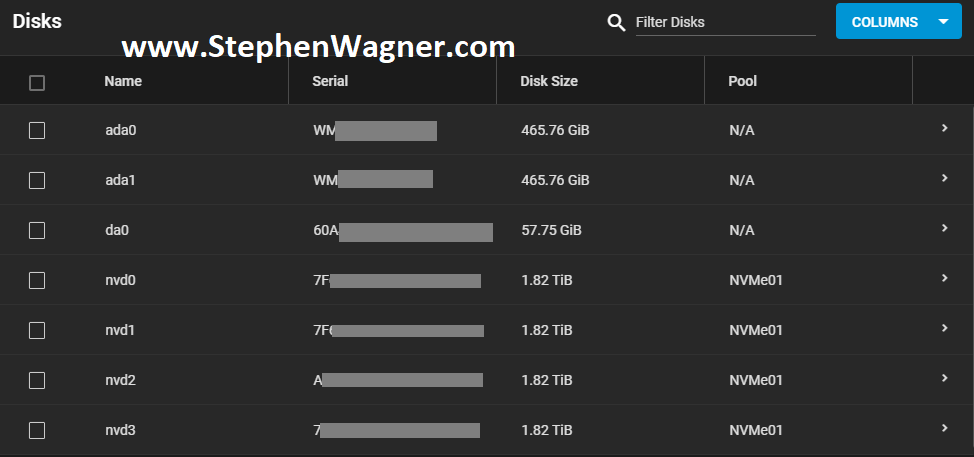
All NVMe drives were recognized, along with the 2 HDDs I had in the front Hot-swap bays (sitting on an HP B120i Controller configured in HBA mode).
TrueNAS NVMe Disks
The 560SFP+ NIC also was detected without any issues and available to configure.
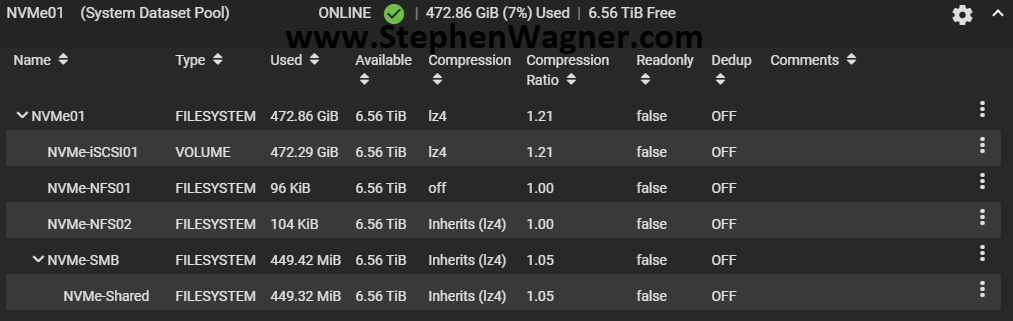
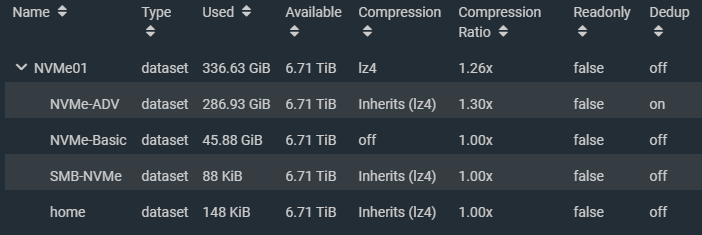
I created a striped pool (no redundancy) of all 4 x 2TB NVMe drives. This gave us around 8TB of usable high speed NVMe storage. I also created some datasets and a zVOL for iSCSI.
NVMe TrueNAS Storage Pool with Datasets and zVol
I chose to go with the defaults for compression to start with. I will be testing throughput and achievable speeds in the future. You should always test this in every and all custom environments as the results will always vary.
Network Configuration
Initial configuration was done via the 1Gb NIC connection to my main LAN network. I had to change this as the 10Gb NIC will be directly connected to the network backbone and needs to access the LAN and Storage VLANs.
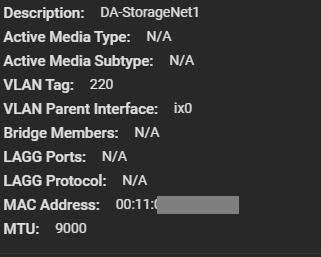
I went ahead and configured a VLAN Interface on VLAN 220 for the Storage network. Connections for iSCSI and NFS will be made on this network as all my ESXi servers have vmknics configured on this VLAN for storage. I also made sure to configure an MTU of 9000 for jumbo frames (packets) to increase performance. Remember that all hosts must have the same MTU to communicate.
10Gb NIC on Storage VLAN
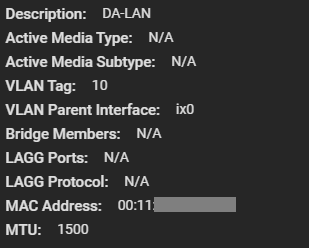
Next up, I had to create another VLAN interface for the LAN network. This would be used for management, as well as to provide Windows File Share (SMB/Samba) access to the workstations on the network. We leave the MTU on this adapter as 1500 since that’s what my LAN network is using.
10Gb NIC on LAN VLAN
As a note, I had to delete the configuration for the existing management settings (don’t worry, it doesn’t take effect until you hit test) and configure the VLAN interface for my LANs VLAN and IP. I tested the settings, confirmed it was good, and it was all setup.
At this point, only the 10Gb NIC is now being used so I went ahead and disconnected the 1Gb network cable.
Sharing Setup and Configuration
It’s now time to configure the sharing protocols that will be used. As mentioned before, I plan on deploying iSCSI, NFS, and Windows File Shares (SMB/Samba).
iSCSI and NFS Configuration
Normally, for a VMware ESXi virtualization environment, I would always usually prefer iSCSI based storage, however I also wanted to configure NFS to test throughput of both with NVMe flash storage.
Earlier, I created the datasets for all my my NFS exports and a zVOL volume for iSCSI.
Note, that in order to take advantage of the VMware VAAI storage directives (enhancements), you must use a zVOL to present an iSCSI target to an ESXi host.
For NFS, you can simply create a dataset and then export it.
For iSCSI, you need to create a zVol and then configure the iSCSI Target settings and make it available.
SMB (Windows File Shares)
I needed to create a Windows File Share for file based storage from Windows computers. I plan on using the Windows File Share for high-speed storage of files for video editing.
Using the dataset I created earlier, I configured a Windows Share, user accounts, and tested accessing it. Works perfect!
Connecting the host
Connecting the ESXi hosts to the iSCSI targets and the NFS exports is done in the exact same way that you would with any other storage system, so I won’t be including details on that in this post.
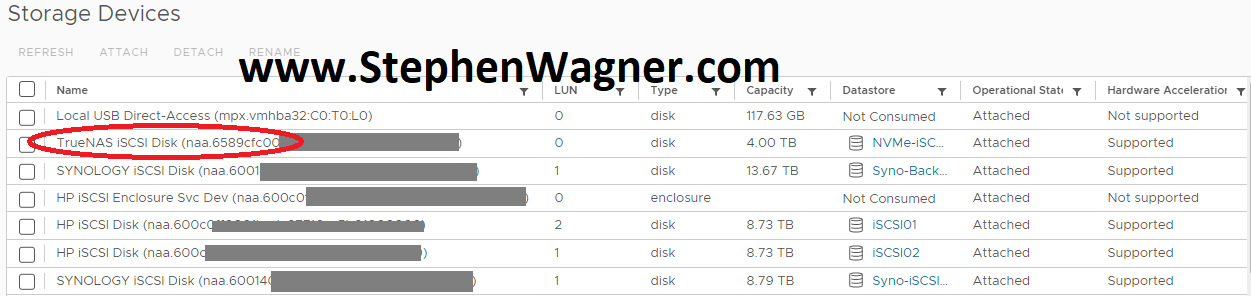
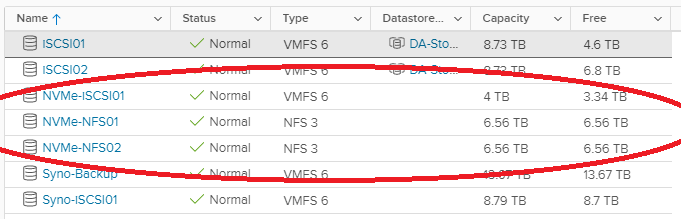
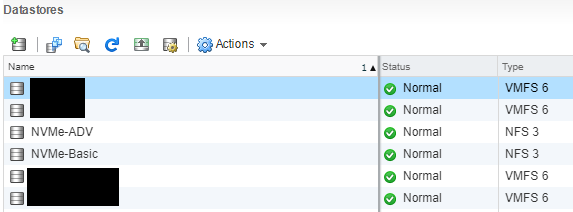
We can clearly see the iSCSI target and NFS exports on the ESXi host.
TrueNAS NVMe iSCSI Target on VMware ESXi Host
NVMe iSCSI and NFS ESXi Datastores
To access Windows File Shares, we log on and map the network share like you would normally with any file server.
Testing
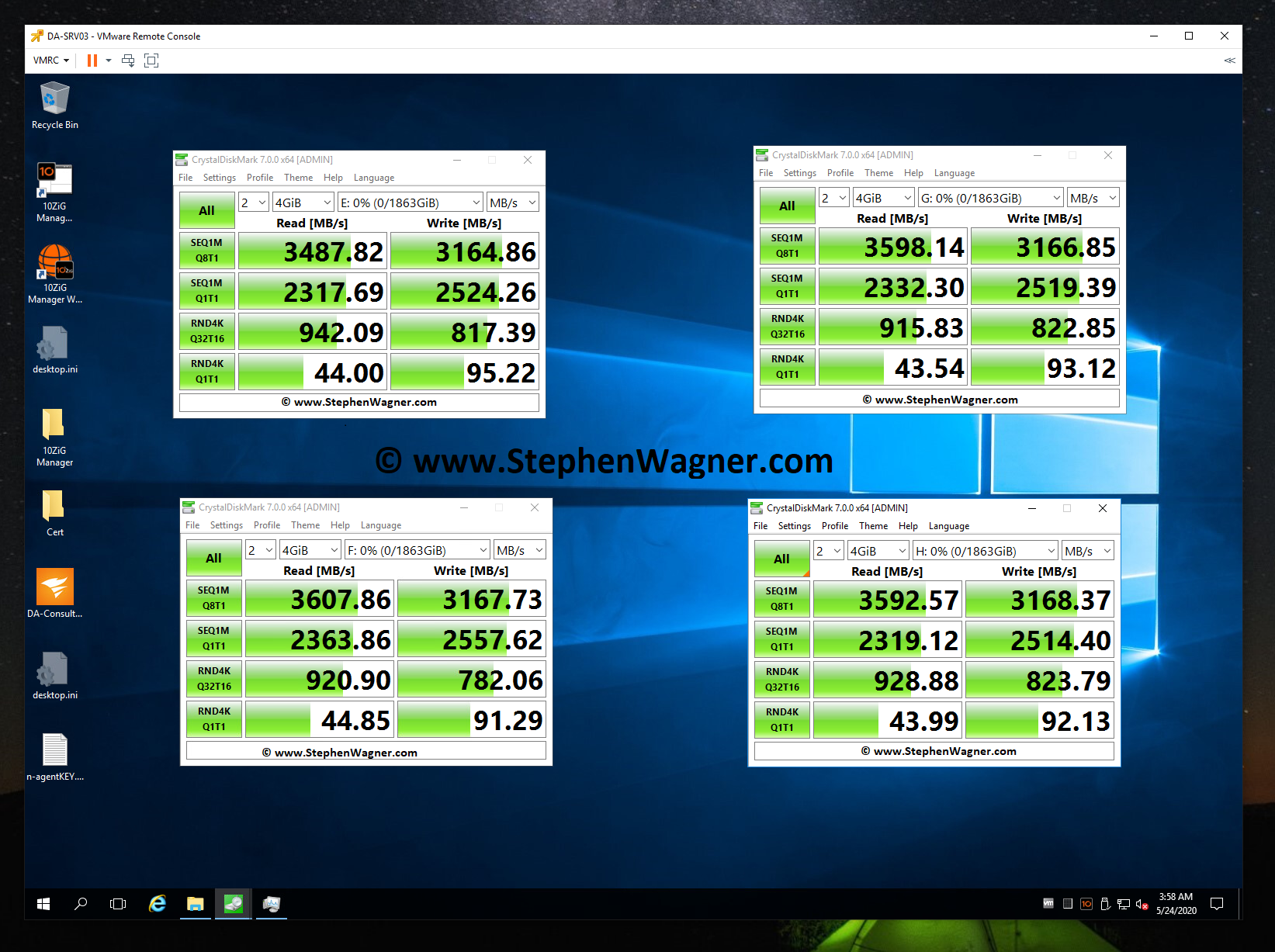
For testing, I moved (using Storage vMotion) my main VDI desktop to the new NVMe based iSCSI Target LUN on the NVMe Storage Server. After testing iSCSI, I then used Storage vMotion again to move it to the NFS datastore. Please see below for the NVMe storage server speed test results.
CrystalDiskMark testing an IOCREST IO-PEX40152 and Sabrent Rocket 4 NVME SSD
CrystalDiskMark testing IOPS on an IOCREST IO-PEX40152 and Sabrent Rocket 4 NVME SSD
Note, that when I performed these tests, my CPU was maxed out and limiting the actual throughput. Even then, these are some fairly impressive speeds. Also, these tests were directly testing each NVMe drive individually.
Moving on to the NVMe Storage Server, I decided to test iSCSI NVMe throughput and NFS NVMe throughput.
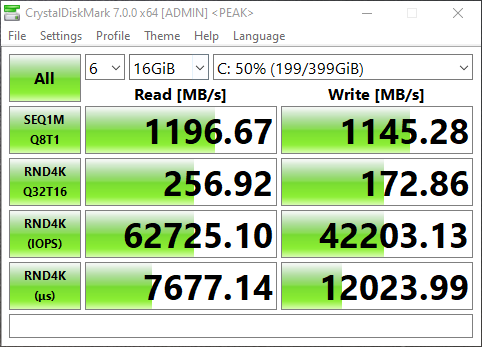
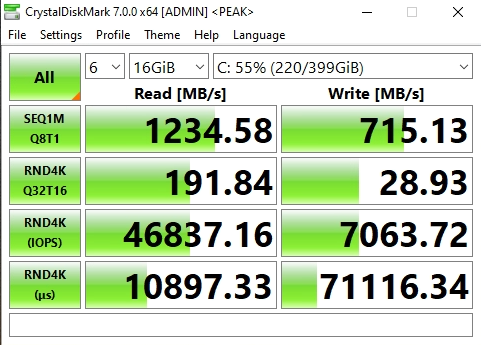
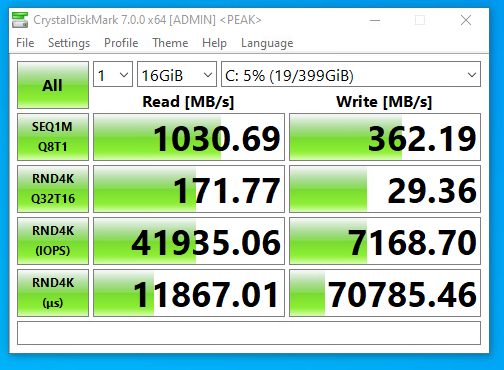
I opened up CrystalDiskMark and started a generic test, running a 16GB test file a total of 6 times on my VDI VM sitting on the iSCSI NVMe LUN.
NVMe Storage Server iSCSI Benchmark with CrystalDiskMark
You can see some impressive speeds maxing out the 10Gb NIC with crazy performance of the NVME storage:
1196MB/sec READ
1145.28MB/sec WRITE (Maxing out the 10GB NIC)
62,725.10 IOPS READ
42,203.13 IOPS WRITE
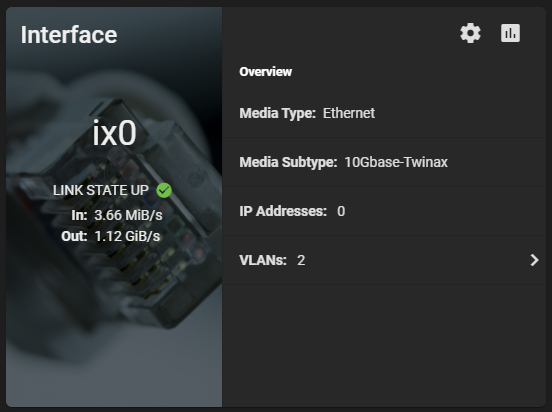
Additionally, here’s a screenshot of the ix0 NIC on the TrueNAS system during the speed test benchmark: 1.12 GiB/s.
TrueNAS NVME Maxing out 10Gig NIC
And remember this is with compression. I’m really excited to see how I can further tweak and optimize this, and also what increases will come with configuring iSCSI MPIO. I’m also going to try to increase the IOPS to get them closer to what each individual NVMe drive can do.
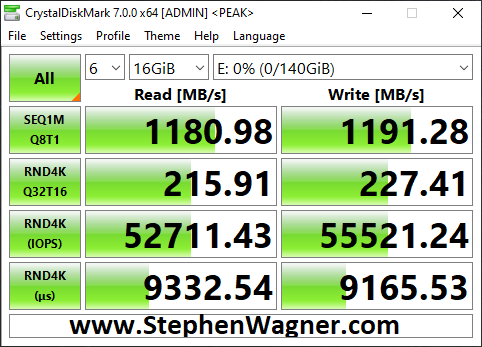
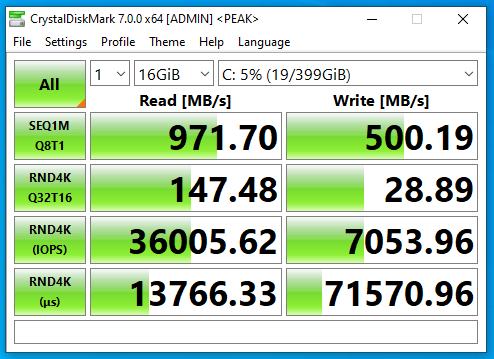
Now on to NFS, the results were horrible when moving the VM to the NFS Export.
NVMe Storage Server NFS Benchmark with CrystalDiskMark
You can see that the read speed was impressive, but the write speed was not. This is partly due to how writes are handled with NFS exports.
Clearly iSCSI is the best performing method for ESXi host connectivity to a TrueNAS based NVMe Storage Server. This works perfect because we’ll get the VAAI features (like being able to reclaim space).
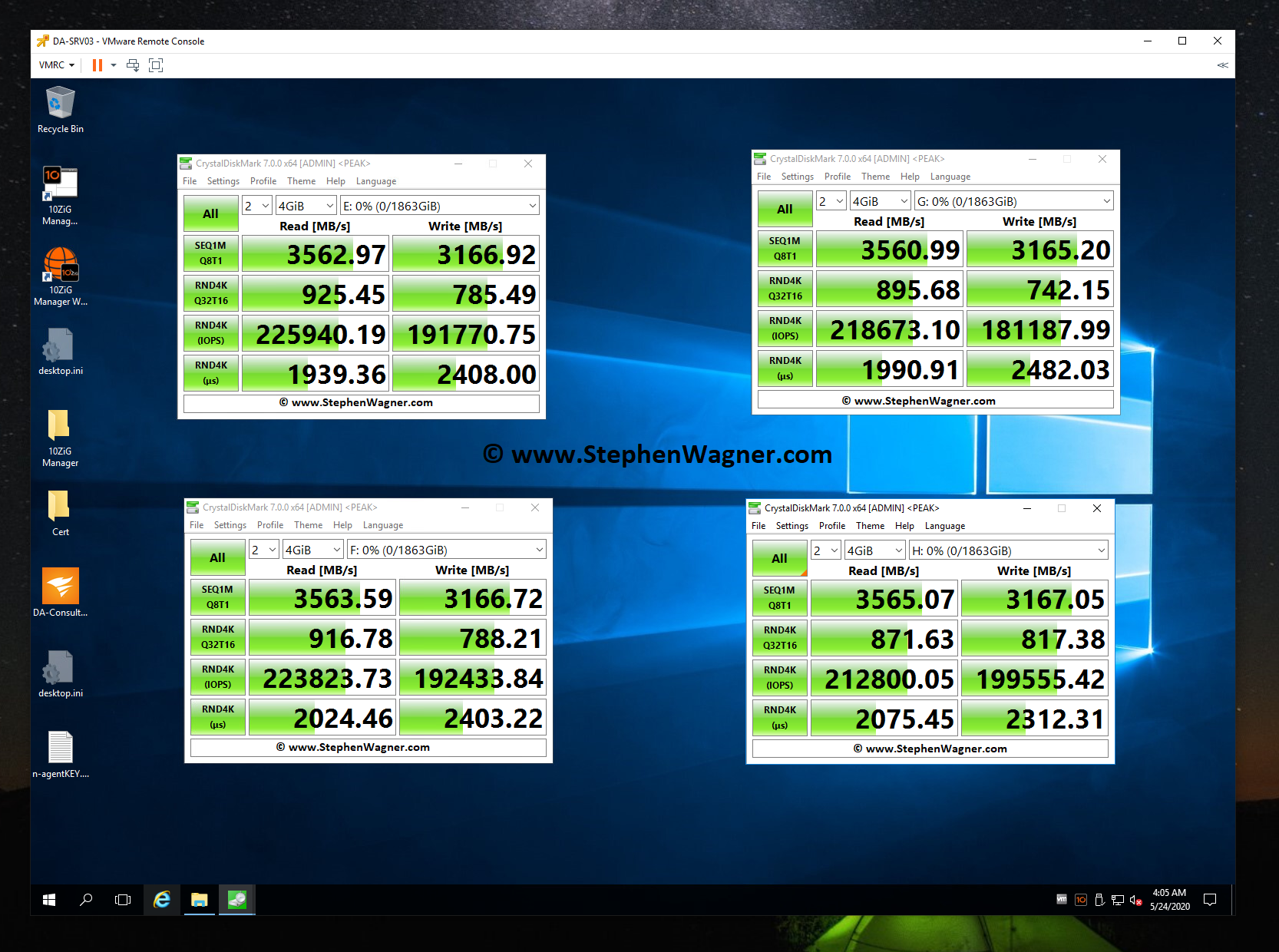
iSCSI MPIO Speed Test
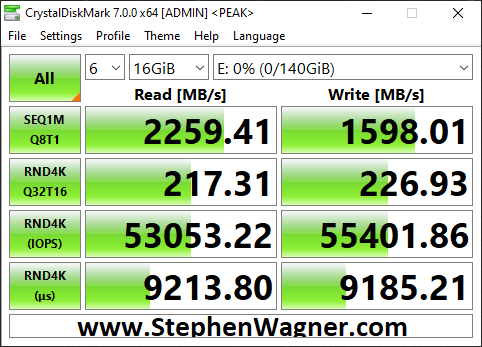
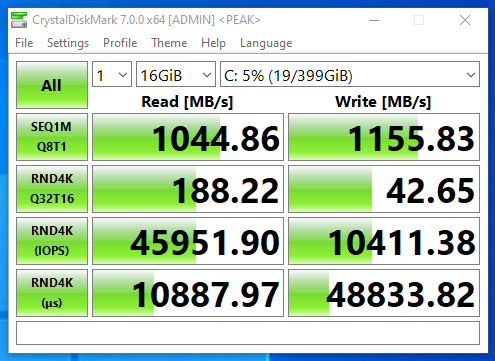
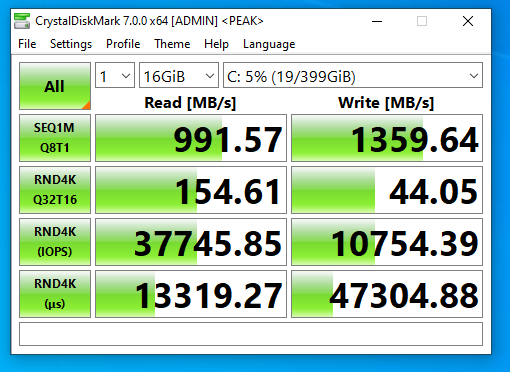
This is more of an update… I was finally able to connect, configure, and utilize the 2nd 10Gbe port on the 560SFP+ NIC. In my setup, both hosts and the TrueNAS storage server all have 2 connections to the switch, with 2 VLANs and 2 subnets dedicated to storage. Check out the before/after speed tests with enabling iSCSI MPIO.
TrueNAS NVME iSCSI MPIO BeforeTrueNAS NVME iSCSI MPIO AfterBefore and After enabling iSCSI MPIO on TrueNAS with NVME Storage
As you can see I was able to essentially double my read speeds (again maxing out the networking layer), however you’ll notice that the write speeds maxed out at 1598MB/sec. I believe we’ve reached a limitation of the CPU, PCIe bus, or something else inside of the server. Note, that this is not a limitation of the Sabrent Rocket 4 NVME drives, or the IOCREST NVME PCIe card.
Moving Forward
I’ve had this configuration running for around a week now with absolutely no issues, no crashes, and it’s been very stable.
Using a VDI VM on NVMe backed storage is lightning fast and I love the experience.
I plan on running like this for a little while to continue to test the stability of the environment before making more changes and expanding the configuration and usage.
Future Plans (and Configuration)
Drive Bays
I plan to populate the 4 hot-swappable drive bays with HPE 4TB MDL drives. Configured with RaidZ1, this should give me around 12TB usable storage. I can use this for file storage, backups, replication, and more.
NVMe Replication
This design was focused on creating non-redundant extremely fast storage. Because I’m limited to a total of 4 NVMe disks in this design, I chose not to use RaidZ and striped the data. If one NVMe drive is lost, all data is lost.
I don’t plan on storing anything important, and at this point the storage is only being used for VDI VMs (which are backed up), and Video editing.
If I can populate the front drive bays, I can replicate the NVMe storage to the traditional HDD storage on a frequent basis to protect against failure to some level or degree.
Version 3 of the NVMe Storage Server
More NVMe and Bigger NVMe – I want more storage! I want to test different levels of RaidZ, and connect to the backbone at even faster speeds.
NVME Drives with PLP (Power Loss Prevention) for data security and protection.
Dual Power Supply
Let me know your thoughts and ideas on this setup!
Need to add 5 SATA drives or SSDs to your system? The IO-PCE585-5I is a solid option!
The IO-PCE585-5I PCIe card adds 5 SATA ports to your system via a single PCIe x4 card using 2 PCIe lanes. Because the card uses PCIe 3.1a, this sounds like a perfect HBA to use to add SSD’s to your system.
This card can be used in workstations, DIY NAS (Network Attached Storage), and servers, however for the sake of this review, we’ll be installing it in a custom built FreeNAS system to see how the card performs and if it provides all the features and functionality we need.
IOCREST IO-PCE585-5I PCIe Card
A big thank you to IOCREST for shipping me out this card to review, they know I love storage products! 🙂
Use Cases
The IO-PCE585-5I card is strictly an HBA (a Host Bus Adapter). This card provides JBOD access to the disks so that each can be independently accessed by the computer or servers operating system.
Typically HBAs (or RAID cards in IT mode) are used for storage systems to provide direct access to disks, so that that the host operating system can perform software RAID, or deploy a special filesystem like ZFS on the disks.
The IOCREST IO-PCE585-5I is the perfect card to accomplish this task as it supports numerous different operating systems and provides JBOD access of disks to the host operating system.
In addition to the above, the IO-PCE585-5I provides 5 SATA 6Gb/s ports and uses PCIe 3 with 2 PCIe lanes, to provide a theoretical maximum throughput close to 2GB/s, making this card perfect for SSD use as well!
Need more drives or SSDs? With the PCIe 2x interface, simply just add more to your system!
While you could use this card with Windows software RAID, or Linux mdraid, we’ll be testing the card with FreeNAS, a NAS system built on FreeBSD.
This card is also marketed as the SI-PEX40139 and IO-PEX40139 Part Numbers.
IO-PCE585-5I Specifications
Let’s get in to the technical details and specs on the card.
IO-PCE585-5I (IO-PEX40139) PCIe Card
According to the packaging, the IO-PCE585-5I features the following:
Supports up to two lanes over PCIe 3.0
Complies with PCI Express Base Specification Revision 3.1a.
Supports PCIe link layer power saving mode
Supports 5 SATA 6Gb/s ports
Supports command-based and FIS-based for Port Multipliers
Complies with SATA Specification Revision 3.2
Supports AHCI mode and IDE programming interface
Supports Native Command Queue (NCQ)
Supports SATA link power saving mode (partial and slumber)
Supports SATA plug-in detection capable
Supports drive power control and staggered spin-up
Supports SATA Partial / Slumber power management state
Supports SATA Port Multiplier
Whats included in the packaging?
1 × IO-PCE585-5I (IO-PEX40139) PCIe 3.0 card to 5 SATA 6Gb/s
1 × User Manual
5 × SATA Cables
1 x Low Profile Bracket
1 x Driver CD (not needed, but nice to have)
Unboxing, Installation, and Configuration
It comes in a very small and simple package.
IO-PCE585-5I Retail Box
Opening the box, you’ll see the package contents.
IO-PCE585-5I Box Contents Unboxed
And finally the card. Please note that it comes with the full-height PCIe bracket installed. It also ships with the half-height bracket and can easily be replaced.
IO-PCE585-5I (SI-PEX40139) PCIe Card
Installation in FreeNAS Server and cabling
We’ll be installing this card in to a computer system, in which we will then install the latest version of FreeNAS. The original plan is to connect the IO-PCE585-5I to a 5-Bay SATA Hotswap backplane/drive cage full of Seagate 1TB Barracuda Hard Drives for testing.
The card installed easily, however we ran in to an issue when running the cabling. The included SATA cables have right angel connectors on the end that connects to the drive, which stops us from being able to connect them to the backplane’s connectors. To overcome this we could either buy new cables, or directly connect to the disks. I chose the latter.
I installed the card in the system, and booted it up. The HBA’s BIOS was shown.
IO-PCE585-5I BIOS
I then installed FreeNAS.
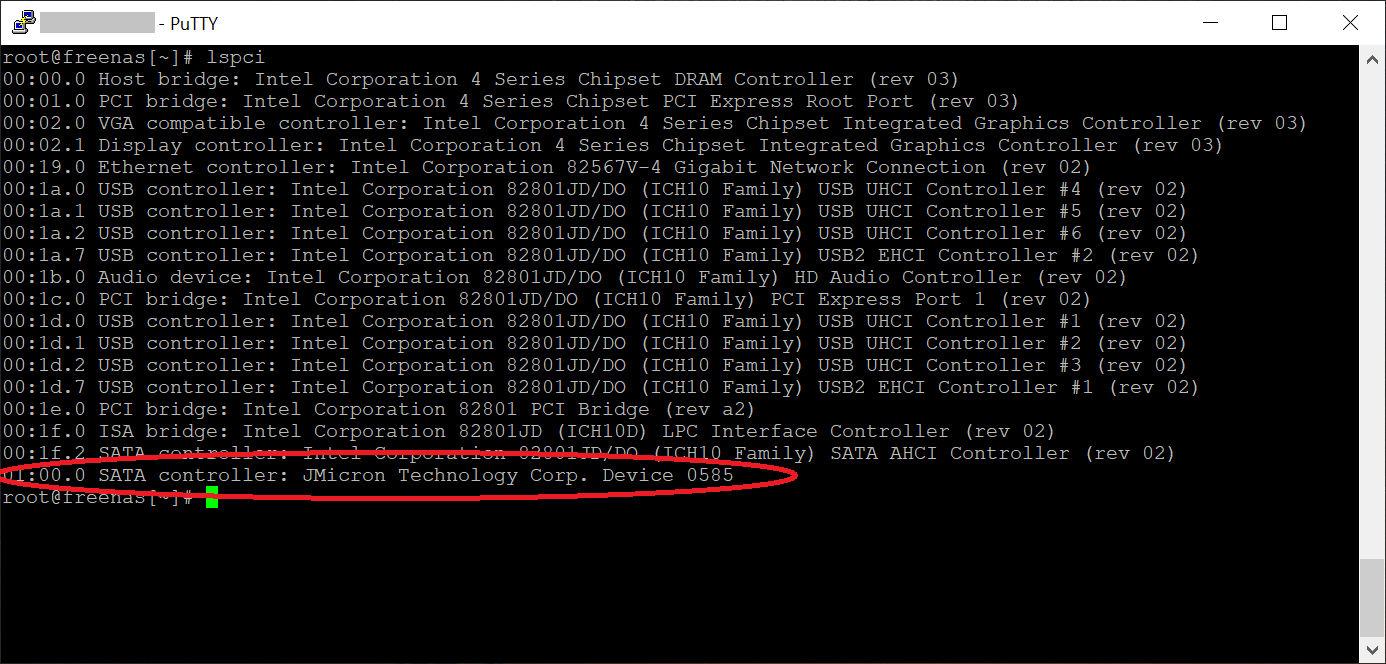
Inside of the FreeNAS UI the disks are all detected! I ran an “lspci” to see what the controller is listed as.
IO-PCE585-5I FreeNAS lspci
SATA controller: JMicron Technology Corp. Device 0585
I went ahead and created a ZFS striped pool, created a dataset, and got ready for testing.
Speedtest and benchmark
Originally I was planning on providing numerous benchmarks, however in every case I hit the speed limit of the hard disks connected to the controller. Ultimately this is great because the card is fast, but bad because I can’t pinpoint the exact performance numbers.
To get exact numbers, I may possibly write up another blog post in the future when I can connect some SSDs to test the controllers max speed. At this time I don’t have any immediately available.
One thing to note though is that when I installed the card in a system with PCIe 2.0 slots, the card didn’t run at the expected speed limitations of PCIe 2.0, but way under. For some reason I could not exceed 390MB/sec (reads or writes) when technically I should have been able to achieve close to 1GB/sec. I’m assuming this is due to performance loss with backwards compatibility with the slower PCIe standard. I would recommend using this with a motherboard that supports PCIe 3.0 or higher.
The card also has beautiful blue LED activity indicators to show I/O on each disk independently.
IO-PCE585-5I LED Activity Indicators
After some thorough testing, the card proved to be stable and worked great!
Additional Notes & Issues
Two additional pieces of information worth noting:
IO-PCE585-5I Chipset – The IO-PCE585-5I uses a JMicron JMB585 chipset. This chipset is known to work well and stable with FreeNAS.
Boot Support – Installing this card in different systems, I noticed that all of them allowed me to boot from the disks connected to the IO-PCE585-5I.
While this card is great, I would like to point out the following issues and problems I had that are worth mentioning:
SATA Cable Connectors – While it’s nice that this card ships with the SATA cables included, note that the end of the cable that connects to the drive is right-angled. In my situation, I couldn’t use these cables to connect to the 5 drive backplane because there wasn’t clearance for the connector. You can always purchase other cables to use.
Using card on PCIe 2.0 Motherboard – If you use this PCIe 3.0 card on a motherboard with PCIe 2.0 slots it will function, however you will experience a major performance decrease. This performance degradation will be larger than the bandwidth limitations of PCIe 2.0.
Conclusion
This card is a great option to add 5 hard disks or solid state drives to your FreeNAS storage system, or computer for that matter! It’s fast, stable, and inexpensive.
I would definitely recommend the IOCREST IO-PCE585-5I.
Looking at using SSD and NVMe with your FreeNAS or TrueNAS setup and ZFS? There’s considerations and optimizations that must be factored in to make sure you’re not wasting all that sweet performance. In this post I’ll be providing you with my own FreeNAS and TrueNAS ZFS optimizations for SSD and NVMe to create an NVMe Storage Server.
This post will contain observations and tweaks I’ve discovered during testing and production of a FreeNAS ZFS pool sitting on NVMe vdevs, which I have since upgraded to TrueNAS Core. I will update it with more information as I use and test the array more.
FreeNAS/TrueNAS ZFS NVMe SSD Pool with multiple datasets
Considerations
It’s important to note that while your SSD and/or NVMe ZFS pool technically could reach insane speeds, you will probably always be limited by the network access speeds.
With this in mind, to optimize your ZFS SSD and/or NVMe pool, you may be trading off features and functionality to max out your drives. These optimizations may in fact be wasted if you reach the network speed bottleneck.
Some feature you may be giving up may actually help extend the life or endurance of your SSD such as compression and deduplication, as they reduce the number of writes performed on each of your vdevs (drives).
You may wish to skip these optimizations should your network be the limiting factor, which will allow you to utilize these features with no performance or minimal performance degradation to the final client. You should measure your network throughput to establish the baseline of your network bottleneck.
Deploying SSD and NVMe with FreeNAS or TrueNAS
For reference, the environment I deployed FreeNAS with NVMe SSD consists of:
1 x FreeNAS instance running as VM with PCI passthrough to NVMe
10Gb networking between DL360 Servers and network
1Gb network between ML310 and network
Update (May 1st, 2021): Since this blog post was created, I have since used what was learned in my new NVMe Storage Server Project. Make sure you check it out after reading this post!
As mentioned above, FreeNAS is virtualizatized on one of the HPE DL360 Proliant servers and has 8 CPUs and 32GB of RAM. The NVME are provided by VMware ESXi as PCI passthrough devices. There has been no issues with stability in the months I’ve had this solution deployed. It is also still working amazing since upgrading FreeNAS to TrueNAS core.
Sabrent Rocket 4 2TB NVMe SSD on FreeNAS
Important notes:
VMXNET3 NIC is used on VMs to achieve 10Gb networking
Using PCI passthrough, snapshots on FreeNAS VM are disabled (this is fine)
NFS VM datastore is used for testing as the host running the FreeNAS VM has the NFS datastore store mounted on itself.
There are a number of considerations that must be factored in when virtualization FreeNAS and TrueNAS however those are beyond the scope of this blog post. I will be creating a separate post for this in the future.
Use Case (Fast and Risky or Slow and Secure)
The use case of your setup will depict which optimizations you can use as some of the optimizations in this post will increase the risk of data loss (such as disabled sync writes and RAIDz levels).
Fast and Risky
Since SSDs are more reliable and less likely to fail, if you’re using the SSD storage as temporary hot storage, you could simply using striping to stripe across multiple vdevs (devices). If a failure occurred, the data would be lost, however if you’re were just using this for “staging” or using hot data and the risk was acceptable, this is an option to drastically increase speeds.
Example use case for fast and risky
VDI Pool for clones
VMs that can be restored easily from snapshots
Video Editing
Temporary high speed data dump storage
The risk can be lowered by replicating the pool or dataset to slower storage on a frequent or regular basis.
Slow and Secure
Using RAIDz-1 or higher will allow for vdev (drive) failures, but with each level increase, performance will be lost due to parity calculations.
Example use case for slow and secure
Regular storage for all VMs
Database (SQL)
Exchange
Main storage
Slow and Secure storage is the type of storage found in most applications used for SAN or NAS storage.
SSD Endurance and Lifetime
Solid state drives have a lifetime that’s typically measured in lifetime writes. If you’re storing sensitive data, you should plan ahead to mitigate the risk of failure when the drive reaches it’s full lifetime.
Steps to mitigate failures
Before putting the stripe or RAIDz pool in to production, perform some large bogus writes and stagger the amount of data written on the SSDs individually. While this will reduce the life counter on the SSDs, it’ll help you offset and stagger the lifetime of each drives so they don’t die at the same time.
If using RAIDz-1 or higher, preemptively replace the SSD before the lifetime is hit. Do this well in advance and stagger it to further create a different between the lifetime of each drive.
Decommissioning the drives preemptively and early doesn’t mean you have to throw them away, this is just to secure the data on the ZFS pool. You can can continue to use these drives in other systems with non-critical data, and possibly use the drive well beyond it’s recommended lifetime.
Compression and Deduplication
Using compression and deduplication with ZFS is CPU intensive (and RAM intensive for deduplication).
The CPU usage is negligible when using these features on traditional magnetic storage (traditional magentic platter hard drive storage) because when using traditional hard drives, the drives are the performance bottleneck.
SSD are a total different thing, specifically with NVMe. With storage speeds in the gigabytes per second, CPUs cannot keep up with the deduplication and compression of data being written and become the bottleneck.
I performed a simple test comparing speeds with compression and dedupe with the same VM running CrystalDiskMark on an NFS VMware datastore running over 10Gb networking. The VM was configured with a single drive on a VMware NVME controller.
NVMe SSD with compression and deduplication
CrystalDiskMark on FreeNAS NFS SSD datastore with compression and deduplication
NVMe SSD with deduplication only
CrystalDiskMark on FreeNAS NFS SSD datastore with deduplication only
NVMe SSD with compression only
CrystalDiskMark on FreeNAS NFS SSD datastore with compression only
Now this is really interesting, that we actually see a massive speed increase with compression only. This is because I have a server class CPU with multiple cores and a ton of RAM. With lower performing specs, you may notice a decrease in performance.
NVMe SSD without compression and deduplication
CrystalDiskMark on FreeNAS NFS SSD datastore without compression and deduplication
In my case, the 10Gb networking was the bottleneck on read operations as there was virtually no change. It was a different story for write operations as you can see there is a drastic change in write speeds. Write speeds are greatly increased when writes aren’t being compressed or deduped.
Note that on faster networks, read speeds could and will be affected.
If your network connection to the client application is the limiting factor and the system can keep up with that bottleneck then you will be able to get away with using these features.
Higher throughput with compression and deduplication can be reached with higher frequency CPUs (more Ghz), more cores (for more client connections). Remember that large amounts of RAM are required for deduplication.
Using compression and deduplication may also reduce the writes to your SSD vdevs, prolonging the lifetime and reducing the cost of maintaining the solution.
ZFS ZIL and SLOG
When it comes to writes on a filesystem, there a different kinds.
Synchronous – Writes that are made to a filesystem that are only marked as completed and successful once it has actually been written to the physical media.
Asynchronous – Writes that are made to a filesystem that are marked as completed or successful before the write has actually been completed and committed to the physical media.
The type of write performed can be requested by the application or service that’s performing the write, or it can be explicitly set on the file system itself. In FreeNAS (in our example) you can override this by setting the “sync” option on the zpool, dataset, or zvol.
Disabling sync will allow writes to be marked as completed before they actually are, essentially “caching” writes in a buffer in memory. See below for “Ram Caching and Sync Writes”. Setting this to “standard” will perform the type of write requested by the client, and setting to “always” will result in all writes being synchronous.
We can speed up and assist writes by using a SLOG for ZIL.
ZIL stands for ZFS Intent Log, and SLOG standards for Separated Log which is usually stored on a dedicated SLOG device.
By utilizing a SLOG for ZIL, you can have dedicated SSDs which will act as your intent log for writes to the zpool. On writes that request a synchronous write, they will be marked as completed when sent to the ZIL and written to the SLOG device.
Implementing a SLOG that is slower than the combined speed of your ZFS pool will result in a performance loss. You SLOG should be faster than the pool it’s acting as a ZIL for.
Implementing a SLOG that is faster than the combined speed of your ZFS pool will result in a performance gain on writes, as it essentially act as “write cache” for synchronous writes and will possibly even perform more orderly writes when it commits it to the actual vdevs in the pool.
If using a SLOG for ZIL, it is highly recommend to use an SSD that has PLP (power loss protection) as well as a mirrored set to avoid data loss and/or corruption in the event of a power loss, crash, or freeze.
RAM Caching and Sync Writes
In the event you do not have a SLOG device to provide a ZIL to your zpool, and you have a substantial amount of memory, you can disable sync writes on the pool which will drastically increase write operations as they will be buffered in RAM memory.
Disabling sync on your zpool, dataset, or zvol, will tell the client application that all writes has been complete and committed to disk (HD or SSD) before it has actually done so. This allows the system to cache writes in the system memory.
In the event of a power loss, crash, or freeze, this data will be lost and/or possibly result in corruption.
You would only want to do this if you had the need for fast storage where data loss would is acceptable (such as video editing, a VDI clone desktop pool, etc).
Utilizing a SLOG for ZIL is much better (and safer) then this method, however I still wanted to provide this for informational purposes as it does apply to some use cases.
SSD Sector Size
Traditional drives typically used 512k physical sector sizes. Newer hard drives and SSDs use 4k sectors, but often emulate 512k logical sectors (called 512e) for compatibility. SSD’s specifically sometimes ship with 512e to increase compatibility with operating systems and the ability to clone your old drive to the new SSD during migrations.
When emulating 512k logical sectors on an HD or SSD that uses 4k physical native sectors, an operation that writes 4k will result in 4 operations instead of 1. This increases overhead and could result in reduced IO and speed, as well as create more wear on the SSD when performing writes.
Some HDs and SSDs come with utilities or tools to change the sector size of the drive. I highly recommend changing it to it’s native sector size.
iSCSI vs NFS
Technically faster speeds should possible using iSCSI instead of NFS, however special care must be made when using iSCSI.
If you’re using iSCSI and the host that is virtualizing the FreeNAS instance is also mounting the iSCSI VMFS target that it’s presenting, you must unmount this iSCSI volume every time you go plan to shut down the FreeNAS instance, or the entire host that is hosting it. Unmounting the iSCSI datastore also means unregistering any VMs that reside on it.
VMware ESXi with virtualized FreeNAS as NFS datastore
If you simply shutdown the FreeNAS instance that’s hosting the iSCSI datastore, this will result in a improper unclean unmount of the VMFS volume and could lead to data loss, even if no VMs are running.
NFS provides a cleaner mechanism, as the FreeNAS handles the unmount of the base filesystem cleanly on shutdown and to the ESXi hosts it appears as an NFS disconnect. If VMs are not running (and no I/O is occuring) when the FreeNAS instance is shut down, data loss is not a concern.
iSCSI MPIO (Multipath I/O)
If your TrueNAS server isn’t virtualized, I’d recommend going with iSCSI because you can configure MPIO (Multipath I/O), which allows redundancy as well as round robin load balancing across multiple connections to the iSCSI target. For example, with 2 x 10Gbe NICs, you should be able to achieve redundancy/failover, as well as 20Gbe combined speeds. If you had 4 x 10Gbe, then you could achieve 40Gbps combined.
Never use LAG or LACP when you want fully optimized NFS, pNFS, or iSCSI MPIO.
Jumbo Frames
Since you’re pushing more data, more I/O, and at a faster pace, we need to optimize all layers of the solution as much as possible. To reduce overhead on the networking side of things, if possible, you should implement jumbo frames.
Instead of sending many smaller packets which independently require acknowledgement, you can send fewer larger packets. This significantly reduces overhead and allows for faster speed.
In my case, my FreeNAS instance will be providing both NAS and SAN services to the network, thus has 2 virtual NICs. On my internal LAN where it’s acting as a NAS (NIC 1), it will be using the default MTU of 1500 byte frames to make sure it can communicate with workstations that are accessing the shares. On my SAN network (NIC 2) where it will be acting as a SAN, it will have a configured MTU of 9000 byte frames. All other devices (SANs, client NICs, and iSCSI initiators) on the SAN network have a matching MTU of 9000.
Additional Notes
Please note that consumer SSDs usually do not have PLP (Power Loss Prevention). This means that in the event of a power failure, any data sitting on the write cache on the SSD may be lost. This could put your data at risk. Using enterprise solid state drives remedies this issue as they often come with PLP.
Conclusion
SSD’s are great for storage, whether it be file, block, NFS, or iSCSI! It’s in my opinion that NVMe and all flash arrays is where the future of storage is going.
I hope this information helps, and if you feel I left anything out, or if anything needs to be corrected, please don’t hesitate to leave a comment!
So you want to add NVMe storage capability to your HPE Proliant DL360p Gen8 (or other Proliant Gen8 server) and don’t know where to start? Well, I was in the same situation until recently. However, after much research, a little bit of spending, I now have 8TB of NVMe storage in my HPE DL360p Gen8 Server thanks to the IOCREST IO-PEX40152.
Unsupported you say? Well, there are some of us who like to live life dangerously, there is also those of us with really cool homelabs. I like to think I’m the latter.
PLEASE NOTE: This is not a supported configuration. You’re doing this at your own risk. Also, note that consumer/prosumer NVME SSDs do not have PLP (Power Loss Prevention) technology. You should always use supported configurations and enterprise grade NVME SSDs in production environments.
Update – May 2nd 2021: Make sure you check out my other post where I install the IOCREST IO-PEX40152 in an HPE ML310e Gen8 v2 server for Version 2 of my NVMe Storage Server.
Update – June 21 2022: I’ve received numerous comments, chats, and questions about whether you can boot your server or computer using this method. Please note that this is all dependent on your server/computer, the BIOS/EFI, and capabilities of the system. In my specific scenario, I did not test booting since I was using the NVME drives purely as additional storage.
DISCLAIMER: If you attempt what I did in this post, you are doing it at your own risk. I won’t be held liable for any damages or issues.
NVMe Storage Server – Use Cases
There’s a number of reasons why you’d want to do this. Some of them include:
Server Storage
VMware Storage
VMware vSAN
Virtualized Storage (SDS as example)
VDI
Flash Cache
Special applications (database, high IO)
Adding NVMe capability
Well, after all that research I mentioned at the beginning of the post, I installed an IOCREST IO-PEX40152 inside of an HPE Proliant DL360p Gen8 to add NVMe capabilities to the server.
IOCREST IO-PEX40152 with 4 x 2TB Sabrent Rocket 4 NVME
At first I was concerned about dimensions as technically the card did fit, but technically it didn’t. I bought it anyways, along with 4 X 2TB Sabrent Rocket 4 NVMe SSDs.
The end result?
HPE DL360p Gen8 with NVME SSD
IMPORTANT: Due to the airflow of the server, I highly recommend disconnecting and removing the fan built in to the IO-PEX40152. The DL360p server will create more than enough airflow and could cause the fan to spin up, generate electricity, and damage the card and NVME SSD.
Also, do not attempt to install the case cover, additional modification is required (see below).
The Fit
Installing the card inside of the PCIe riser was easy, but snug. The metal heatsink actually comes in to contact with the metal on the PCIe riser.
IO-PEX40152 installed on DL360p PCIe Riser
You’ll notice how the card just barely fits inside of the 1U server. Some effort needs to be put in to get it installed properly.
HPE DL360p Gen8 with IO-PEX40152 Installed
There are ribbon cables (and plastic fittings) directly where the end of the card goes, so you need to gently push these down and push cables to the side where there’s a small amount of thin room available.
We can’t put the case back on… Yet!
Unfortunately, just when I thought I was in the clear, I realized the case of the server cannot be installed. The metal bracket and locking mechanism on the case cover needs the space where a portion of the heatsink goes. Attempting to install this will cause it to hit the card.
HPE DL360p Gen8 Case Locking Mechanism
The above photo shows the locking mechanism protruding out of the case cover. This will hit the card (with the IOCREST IO-PEX40152 heatsink installed). If the heatsink is removed, the case might gently touch the card in it’s unlocked and recessed position, but from my measurements clears the card when locked fully and fully closed.
I had to come up with a temporary fix while I figure out what to do. Flip the lid and weight it down.
HPE DL360p Gen8 case cover upside down
For stability and other tests, I simply put the case cover on upside down and weighed it down with weights. Cooling is working great and even under high load I haven’t seen the SSD’s go above 38 Celsius.
The plan moving forward was to remove the IO-PEX40152 heatsink, and install individual heatsinks on the NVME SSD as well as the PEX PCIe switch chip. This should clear up enough room for the case cover to be installed properly.
The fix
I went on to Amazon and purchased the following items:
IOCREST IO-PEX40152 with GLOTRENDS M.2 NVMe SSD Heatsink on Sabrent Rocket 4 NVME
And now we install it in the DL360p Gen8 PCIe riser and install it in to the server.
You’ll notice it’s a nice fit! I had to compress some of the heat conductive goo on the PFX chip heatsink as the heatsink was slightly too high by 1/16th of an inch. After doing this it fit nicely.
Also, note the one of the cable/ribbon connectors by the SAS connections. I re-routed on of the cables between the SAS connectors they could be folded and lay under the card instead of pushing straight up in to the end of the card.
As I mentioned above, the locking mechanism on the case cover may come in to contact with the bottom of the IOCREST card when it’s in the unlocked and recessed position. With this setup, do not unlock the case or open the case when the server is running/plugged in as it may short the board. I have confirmed when it’s closed and locked, it clears the card. To avoid “accidents” I may come up with a non-conductive cover for the chips it hits (to the left of the fan connector on the card in the image).
And with that, we’ve closed the case on this project…
HPE DL360p Gen8 Case Closed
One interesting thing to note is that the NVME SSD are running around 4-6 Celsius cooler post-modification with custom heatsinks than with the stock heatsink. I believe this is due to the awesome airflow achieved in the Proliant DL360 servers.
Conclusion
I’ve been running this configuration for 6 days now stress-testing and it’s been working great. With the server running VMware ESXi 6.5 U3, I am able to passthrough the individual NVME SSD to virtual machines. Best of all, installing this card did not cause the fans to spin up which is often the case when using non-HPE PCIe cards.
This is the perfect mod to add NVME storage to your server, or even try out technology like VMware vSAN. I have a number of cool projects coming up using this that I’m excited to share.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.
Do you accept the use of cookies and accept our privacy policy? AcceptRejectCookie and Privacy Policy
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.